Performance Engineering Series – Tuning for Performance - Case Study - 2
Introduction
After all the comments and the
feedback from the community which has been much encouraging, this is the
second article in the engineering series also aimed at tuning the JVM. In the first one we had delved deep in to
tuning G1GC which can get complex at times depending on the application design
and its intended usage.
Background
In this article today, we will
try to look at simple case of an application running Parallel GC which is
primarily used for UI navigation of a complex micro service based system. Here we are using the terms simple and
complex which might sound contradicting, but just to give a birds eye view,
this application is primarily used for UI side navigation with internal API
based communication with all the supporting micro services. So, this design is light weight and the heavy
lifting is done by the services themselves, so the throughput is quite high and
responsiveness is very important.
In this context, the
immediate thought that would cross ones mind is when are referring to
responsiveness, why not consider moving to G1 which is primarily designed for
that purpose? But before getting to
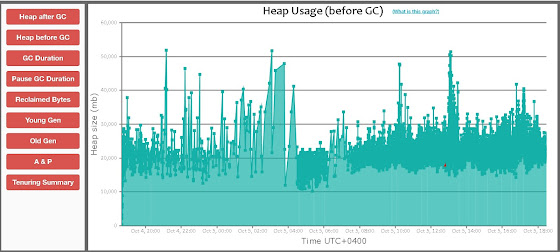
that point, lets look at the current GC data from the application under
discussion with some graphs.
The graphs are courtsey of GCEasy
and full credits to them.
Investigation and findings
The throughput, as can be
seen is at this theoretical maximum with the GC pause time being in few
milliseconds. Sounds excellent?
Yes, then why are we even
trying to tune it?


From the heap usage graphs, it can be seen that a lot of it
is trying to be reclaimed and due to the level of activity and the promotion of
the objects, a Full GC is becoming necessary which is being triggered as a part
of the regular JVM Ergonomics.






Now, the primary question here - what is there to tune and how do we do it?
By the usage pattern, we can infer that the heap is not
sufficiently sized because of which frequent major collections are being
triggered to free up heap for the application. With this inference, the immediate thing that needs to be done is to resize the heap. If yes, then by what
amount?
In Parallel GC, as everything is STW, heap size and the
pause times are directly proportional and we will need to tread carefully. Too large a heap will mean equally large pause
times which can be detrimental to the applications performance, especially for a UI type application.
Recommendation and findings
Our aim is to delay the Major GC events as long as possible
but also try to keep them short. As we are already dealing with very short pause times, so, the immediate
suggestion that was recommended to resize the heap from the current allocation of
16GB to 30GB.
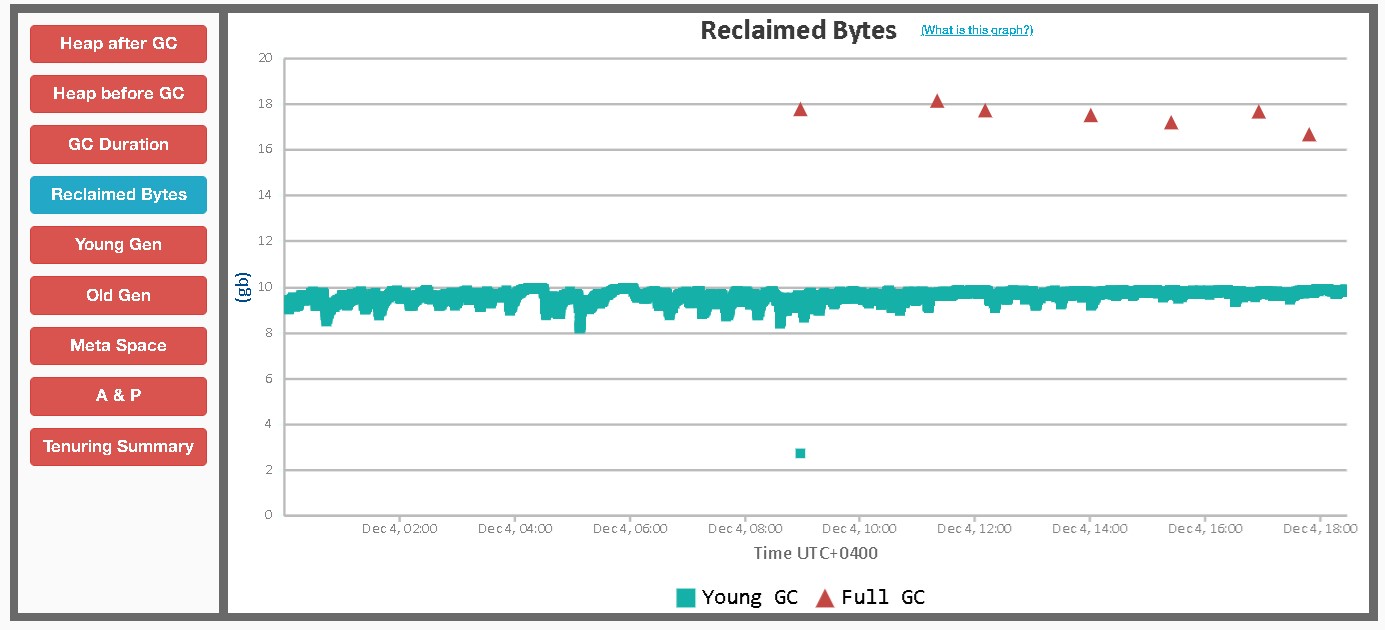
Once the change was put in, the immediate thing to do was to go back and check if the recommendation went well or if it caused further problems. Let us look at the some more GC graphs to confirm -


Some more graphs for further learning and comparison with earlier ones -





Conclusion
In conclusion and as a learning point, tuning would not
necessarily mean doing something radical, but something as simple as whatwe have done in this case to get an overall better outcome.
I hope this article has provided something more to learn and
also must have presented a different approach to the problem.
Signing off for now and please tune in again for another interesting journey in Performance Engineering. Till then stay safe and keep learning!